Main Purpose
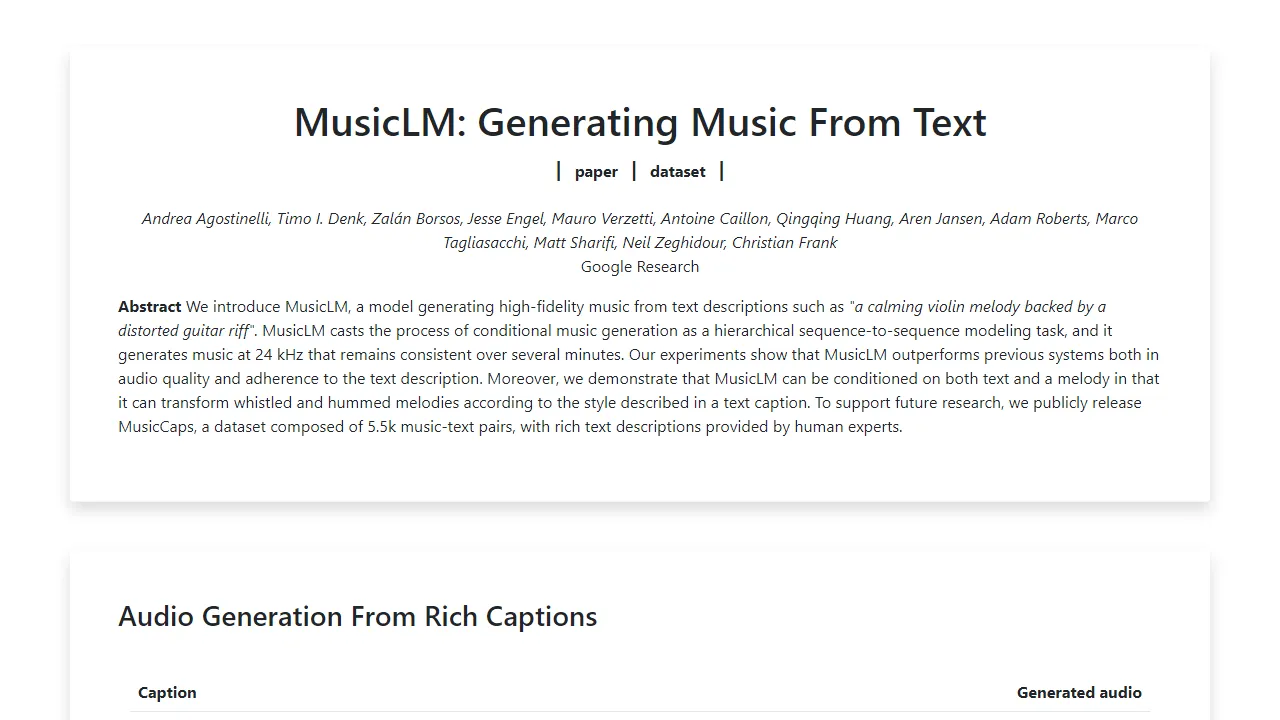
The main purpose of the website is to showcase examples and demonstrations of MusicLM, a framework for generating music from text.
Key Features
- Music Generation: MusicLM allows users to generate music based on text prompts.
- Language Modeling: The framework utilizes language modeling techniques to generate coherent and natural music continuations.
- Speech Continuation: MusicLM can generate speech continuations that preserve speaker identity, prosody, and semantic coherence.
- Acoustic Generation: The framework can generate acoustic tokens based on semantic tokens extracted from original samples.
- Unconditional Generation: MusicLM supports unconditional generation of music without using prompts.
- Piano Continuation: The framework can generate coherent piano music continuations, even without any symbolic representation of music.
Use Case
- Music Composition: MusicLM can be used by composers and musicians to generate musical ideas and explore different compositions based on text prompts.
- Speech Generation: The framework can be used to generate speech continuations that maintain speaker identity and semantic coherence, which can be useful in applications like voice assistants or dialogue systems.
- Acoustic Modeling: MusicLM's acoustic generation capabilities can be utilized in tasks such as audio synthesis, voice conversion, or audio post-processing.